


Modernizing public Hockey analytics part 1 - Data engineering
A data engineering journey towards modernizing NHL data
Sometimes, you need to get data from a website that isn’t yours. If you’re lucky, there will be an API available that you can request data from directly.
Notwithstanding the fact that the data-gatherer is at the mercy of the developers who put together the API, it is an ideal way to extract data from a website.

When direct access is not possible, web scraping is (sometimes) an option!
Web-scraping (or web harvesting) is the process of extracting data from websites by sifting through a website’s source code. I won’t be covering the basics in this article, but here is a good place to start if this concept is new to you: Web Scraping Basics.
In 2021, and depending on your programming language of choice, you have some great options!
If you are working in R, the tidyverse/rVest package is a great option. To learn more, check out a previous post I wrote on how to build a cheap and cheerful eBay web-scraper in R using rVest.
In Python, several libraries can do the trick. Some of the most popular options include Requests, BeautifulSoup, Scrapy, and Selenium. For a brief overview of the best Python web-scraping tools, check out the embedded video below:
In this post, we will be using the Requests and BeautifulSoup Python libraries to web-scrape a single page of Amazon product review data.
We will be using the Chrome browser and reviewing some inspection techniques to assist with the job of finding the data we want to scrape. In addition, we will be using Splash to return HTML from the products we are trying to scrape, and Docker to containerize and run Splash (more on this later).
Credit to John Watson Rooney who provided the code in github from which this tutorial is adapted from. He has some excellent content Python web-scraping content on YouTube. I would encourage you to check it out if this topic interests you.
Splash is a lightweight web browser and javascript rendering service that makes web-scraping in python easy. We will be using it to send off HTTP requests, and it will render the page and return the information that we are looking for.
It also plays very nicely with the Requests and BeautifulSoup libraries, but it does require installing and running Docker.
Docker is a popular and open platform for developing and running applications. What makes it unique is how lightweight and fast it is, which is because of its containerized infrastructure.
To setup Docker and Splash, watch the video below:
To learn more about Docker, check out The Simple Engineer’s easy to follow introduction video to Docker and Docker Containers.
We are going to be working with three libraries: requests, bs4 (BeautifulSoup), and pandas. We can use pip to install the package (if you don’t have pip, follow this tutorial.
Run the following commands in the same directory that contains your python interpreter:
pip install requests
pip install bs4
pip install pandasFire up your Python notebook or interpreter of choice. My personal favourite at the moment is Microsoft’s Visual Studio Code, although PyCharm is another goodie.
If you don’t have either, you can always work in a notebook. I’ve enjoyed the simplicity of Google Colab.
Now is when the fun begins.
We are going to scraping data from this Amazon product reviews page.
First, we will want to import our libraries and specify the URL we will be working with.
# import libraries
import requests
from bs4 import BeautifulSoup
# URL setup and HTML request
url = 'https://www.amazon.ca/Sony-WF-1000XM3-Industry-Canceling-Wireless/product-reviews/B07T81554H/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews'Next, we want to store the HTTP response in a variable.
If we didn’t care about using Splash, we could simply make the HTTP request ourselves.
# request HTTP locally, store in a variable
r = requests.get(url) But since using Splash is a good practice (and easy to set up in python), let’s add some parameters to the above chunk of code.
All we will be doing is sending our HTTP request to Splash, and have it save and return the response to us.
# send HTTP request to Splash, store in a variable
r = requests.get('http://localhost:8050/render.html', params = {'url': url, 'wait' : 2}) # wait 2 mins maxWe can print the results to test that our Docker container is set up properly.
# print the HTTP result
print(r.text)Soup time!
We are going to use the BeautifulSoup library to parse out raw HTML content stored in the variable r.
# parse out HTML content
soup = BeautifulSoup(r.text, 'html.parser')Like before, it’s always good to print out the results as we add to our code. Let’s peak at the title of the page we just scraped and parsed.
# print the title of the text we just scraped
print(soup.title.text)We are going to be scraping for the following data points:
Before we write any code, we need to find where on the web page our data lives. In other words, we need to figure out what we need to tell python to look for in our soup.
This part is all about finding those unique elements embedded in the source code that we can use to get the data that we want.
On the reviews page, open up the inspector and activate the element inspector (CTRL + SHIFT + C). This will allow us to find the tag that is most appropriate to identify the data that we are looking for.
Spend some time getting familiar with the elements in the CSS - there is usually more than 1 way to identify an element!
Need a CSS refresher? Brush up with CSS Dinner.
After browsing around, you will notice that each of the data points we are interested in scraping are found within div containers.
Moreover, each of them uses the alias data-hook in the a-tag, and values for each start with the term review.

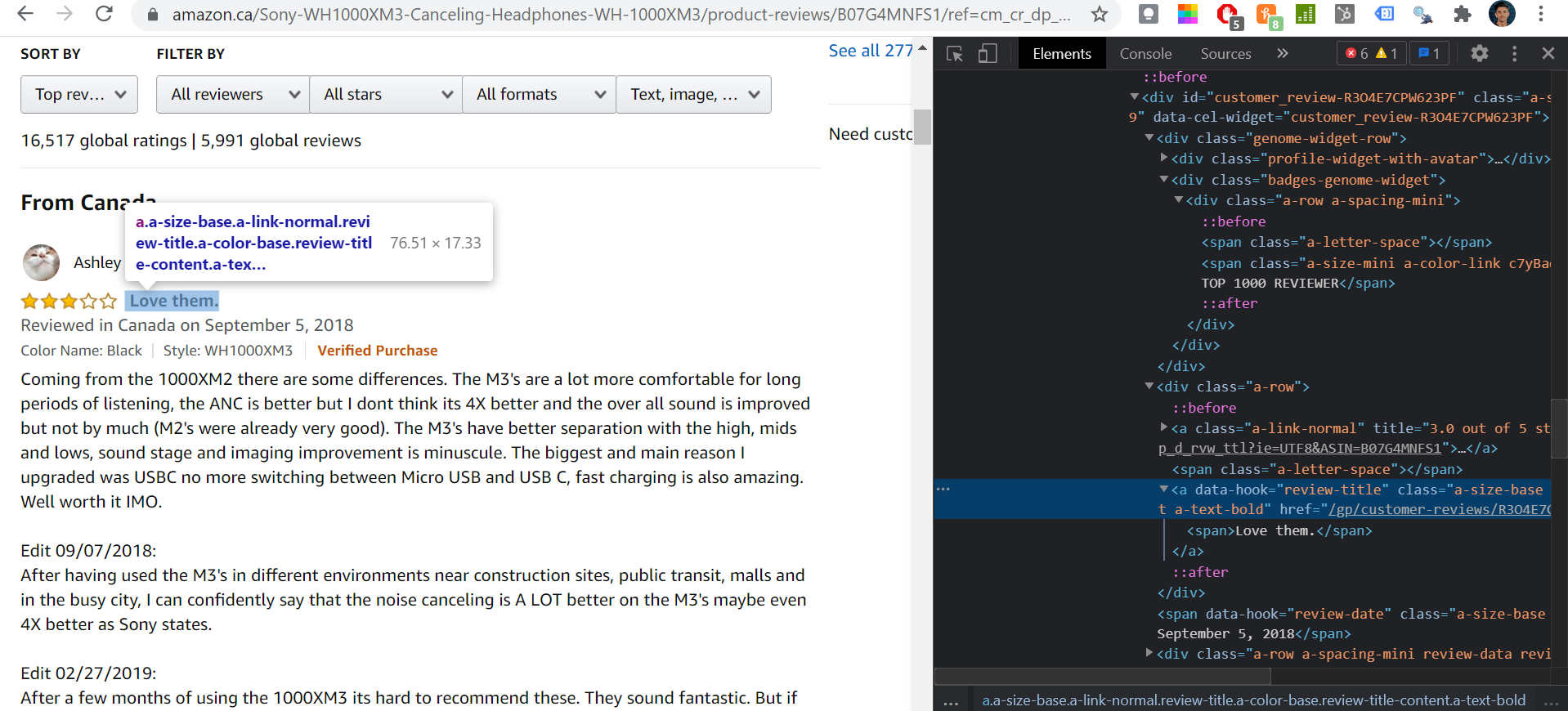


Now, it’s time to test it out in Python.
We will start with the product name, which we actually got a glimpse of earlier.
# scrape the product name found in the title, strip text, print out results
product = soup.title.text.strip()
print(product)If we did this correctly, we should see the result Amazon.ca:Customer review Sony WF-1000XM3/B Industry Leading Noise Canceling Truly Wireless Earbuds, Black.
Let’s add in a text.replace() to clean it up.
# scrape the product name found in the title, replace & strip text, print out results
product = soup.title.text.replace('Amazon.ca:Customer reviews: ', '').strip()
print(product)Next up is the review title. For this one, we will make use of the soup.find() command.
# scrape the review title, strip text, print out results
title = soup.find('a', {'data-hook': 'review-title'}).text.strip()
print(title)After that is date.
# scrape the review date, strip text, print out results
date = soup.find('span', {'data-hook': 'review-date'}).text.strip()
print(date)A correct result should yield something like Reviewed in Canada on May 12, 2021.
Like before, we can leverage the text.replace() function so that we only see the date.
# scrape the review date, replace and strip text, print out results
date = soup.find('span', {'data-hook': 'review-date'}).text.replace('Reviewed in Canada on', '').strip()
print(date)Rating is next (star rating). Here, we will scrape the data & replace the text all at once.
# scrape the review rating, replace and strip text, wrap in a float (decimal), print out results
rating = float(soup.find('i', {'data-hook': 'review-star-rating'}).text.replace('out of 5 stars', '').strip())
print(rating)Saving the best for last - next up we scrape the review text.
# scrape the review text, strip text, print out results
text = soup.find('span', {'data-hook': 'review-body'}).text.strip(),
print(text)To scrape all the fields we want at once, we can run the following:
# scrape desired fields for a single review
data = []
review = {
'product': soup.title.text.replace('Amazon.ca:Customer reviews: ', '').strip(),
'title': soup.find('a', {'data-hook': 'review-title'}).text.strip(),
'date': soup.find('span', {'data-hook': 'review-date'}).text.strip(),
'rating': float(soup.find('i', {'data-hook': 'review-star-rating'}).text.replace('out of 5 stars', '').strip()),
'text' : soup.find('span', {'data-hook': 'review-body'}).text.strip(),
}
data.append(review)
print(data)Success!
But, all we got returned was a single review. Let’s extend that chunk of code to loop through each review item on the page.
# initialize empty list df
data = []
# for every item in review, scrape the following data points and store as a list called review
for item in reviews:
review = {
# scrape product name
'product': soup.title.text.replace('Amazon.ca:Customer reviews: ', '').strip(),
# scrape the review title
'title': item.find('a', {'data-hook': 'review-title'}).text.strip(),
# scrape the date (includes the syntax: Reviewed in Canada on...)
'date': item.find('span', {'data-hook': 'review-date'}).text.strip(),
# scrape the star rating, leave as a decimal
'rating': float(item.find('i', {'data-hook': 'review-star-rating'}).text.replace('out of 5 stars', '').strip()),
# scrape the actual review text
'text': item.find('span', {'data-hook': 'review-body'}).text.strip(),
}
data.append(review)
print(df)If we did this correctly, we should have 10 unique results.
Pro tip: run print(len(df)) at the end of your code above to test.
Great Success!

Last but not least, we can save it all to a data frame with some good ol’ pandas.
# save results to a dataframe, then export as CSV
df = pd.DataFrame(data)
df.to_csv(r'sony-headphones.csv', index=False)To review, here is what we just did:
All of this code can be found in my github repo here.
That’s it! We just ran through a very basic example of how to build a single-page web-scraper in Python.
I intend on publishing another post on multi-page web scraping soon, which is another beast entirely.
A data engineering journey towards modernizing NHL data
My take on what it means to be a full-stack analytics professional.
Data science app using Python and Streamlit to visualize sentiment from NHL fans and insiders on Twitter.

{kind=link}